データ型
new_num = int('1')
new_num, type(new_num)
>>> 1 <class 'int'>
num: int = 100
name: str = '100'
num = name
num, type(num)
>>> 1 <class 'str'> int型がstr型に上書きされた
print('Hi', 'Mike', sep=',', end='.\n')
>>> Hi,Mike.
print('hello. \nHow are you?')
>>>hello.
>>>How are you?
print('say "I don\'t know"')
print("say \"I don't know\"")
>>>say "I don't know"
>>>say "I don't know"
print(r'C:\name\name') #rをつけて意図せぬ改行の回避
>>>C:\name\name
word = 'python'
word = 'j' + word[1:]
print(word)
>>>jython
s = 'My name is Mike. Hi Mike.'
print(s.find('Mike')) #Mikeのいち
>>>11
print(s.rfind('Mike')) #後ろのMikeを探してね
>>>20
print(s.count('Mike')) #Mikeの数
>>>2
print(s.capitalize())
>>>My name is mike. hi mike.
print(s.title()) #先頭をcapitalize
>>>My Name Is Mike. Hi Mike.
print(s.upper())
>>>MY NAME IS MIKE. HI MIKE.
print(s.lower())
>>>my name is mike. hi mike.
print(s.replace('Mike', 'Nancy'))
>>>My name is Nancy. Hi Nancy.
name = 'Taro'
family = 'Suzuki'
print(f'My name is {name} {family}. 私は {family} {name}.')
>>>My name is Taro Suzuki. 私は Suzuki Taro.
リスト型
print(help(list)) #使用可能なメソッドが表示されます
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
l[2:5]
>>>[3, 4, 5]
l[::2] #1つ飛ばしで取り出す
>>>[1, 3, 5, 7, 9]
l[::-1] #逆順で取り出す
>>>[10, 9, 8, 7, 6, 5, 4, 3, 2, 1
type(l)
>>>list
len(l)
>>>10
list('abcdef') #リスト化する
>>>['a', 'b', 'c', 'd', 'e', 'f']
a = ['a', 'b', 'c']
n = ['1', '2', '3']
x = [a, n]
print(x)
>>>[['a', 'b', 'c'], ['1', '2', '3']]
x[0][0]
>>>'a'
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
l[2:5] = ['C', 'D', 'E']
print(l)
>>>[1, 2, 'C', 'D', 'E', 6, 7, 8, 9, 10]
"""要素の削除"""
n = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
n.pop(3) #インデックス3を削除
print(n)
>>>[1, 2, 3, 6, 7, 8, 9, 10]
n.pop() #末尾を削除
print(n)
>>>[1, 2, 3, 4, 5, 6, 7, 8, 9]
n.remove(4) 4を削除
print(n)
>>>[1, 2, 3, 5, 6, 7, 8, 9, 10]
del n[0] インデックス0を削除
>>>[2, 3, 4, 5, 6, 7, 8, 9, 10]
n.insert(0, 200)
print(n)
>>>[200, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
""" """
a = ['a', 'b', 'c', 'd', 'e']
b = [1, 2, 3, 4]
a += b
>>>['a', 'b', 'c', 'd', 'e', 1, 2, 3, 4]
a.extend(b)
>>>['a', 'b', 'c', 'd', 'e', 1, 2, 3, 4]
r = [1, 2, 3, 4, 5, 1, 2, 3]
r.index(3) #3はインデックス何番ですか
>>>2
r.index(1, 2) #1をインデックス2番目以降から探してください
>>>5
r.count(3) #3は何個ありますか
>>>2
r = [1, 2, 3, 4, 5, 1, 2, 3]
r.sort()
r
>>>[1, 1, 2, 2, 3, 3, 4, 5]
r.sort(reverse=True)
r
>>>[5, 4, 3, 3, 2, 2, 1, 1]
s = 'My name is Mike.'
splitted = s.split(' ')
print(splitted)
>>>['My', 'name', 'is', 'Mike.']
x = ' '.join(splitted) #半角スペースでくっつける
print(x)
#リストはcopyメソッドを使って値のみコピー
x = [1, 2, 3, 4, 5]
y = x.copy()
y[0] = 100
print('y =', y)
print('x =', x)
>>> y = [100, 2, 3, 4, 5]
>>> x = [1, 2, 3, 4, 5]タプル
タプルは書き換えたくないデータを扱う
#タプルのアンパッキング
num_tuple = (10, 20)
x, y = num_tuple
print(x, y)
>>> 10 20
#こんな時タプルを使う
choose_from_three = ('A', 'B', 'C')
answer = []
answer.append('A')
answer.append('B')
print(choose_from_three)
print(answer)
>>>('A', 'B', 'C')
>>>'A', 'B']
辞書型
#色々な表示
d = {'x': 10, 'y': 20}
dict(x=10, y=20)
dict([('x', 10), ('y', 20)])
取り出し
d['x']
>>>10
d.get('x')
>>>10
d = {'x': 10, 'y': 20}
d.pop('x')
print(d)
>>>{'y': 20}
d['z'] = 200 #追加
d = {'x': 10, 'y': 20}
d2 = {'x': 1000, 'j': 500}
d.update(d2) #更新
d
>>>{'x': 1000, 'y': 20, 'j': 500}
#辞書型は検索しやすい
fruits = {
'apple': 100,
'banana': 200,
'orange': 300
}
print(fruits['apple'])
>>>100集合型
a = {1, 2, 2, 3, 4, 4, 5, 6}
b = {2, 3, 3, 6, 7}
a - b #aからbを除いたもの
a & b #aとbにあるもの
a | b #aまたはbのどちらかにあるもの
a ^ b #aまたはbにあるけれど重複していないもの
a.remove(6) #6を取り除く
a.add(6) #データを追加
a[0] #集合にはインデックスはない
a.clear() #全要素を削除
my_friends = {'A', 'C', 'D'}
A_friends = {'B', 'D', 'E', 'F'}
print(my_friends & A_friends) #集合でかぶる要素
#リストから重複を削除する
f = ['apple', 'banana', 'apple', 'banana']
kind = set(f) #setは集合型への型変換
print(kind)書き方
"""行の分割"""
s = 'aaaaaaaaaaa' \
+ 'bbbbbbbbb'
print(s)
"""複数のelif文"""
x = 10
if x < 0:
print('negative')
elif x == 0:
print('zero')
elif x == 10:
print('10')
else:
print('positive')
"""比較演算子 =="""
a = 1
b = 1
print(a == b)
print(a != b)
"""論理演算子 or"""
a = 1
b = -1
# a > 0またはb > 0が真であれば真
if a > 0 or b > 0:
print('a or b are positive')
"""orを使わない場合"""
# a > 0またはb > 0が真であれば真
if a > 0:
print('a or b are positive')
elif b > 0:
print('a or b are positive')
"""not"""
a = 1
b = 10
if not a == b:
(if a != b:)
print('Not equal')
lesson_package
|
|--utils.py
def say_twice(word):
return word * 2
from lesson_package.utils import say_twice
r = say_twice('hello')
print(r)ファイル操作
s = """\
AAA
BBB
CCC
"""
#書き込み用テキストとしてoutput.txtを用意する
with open('test.txt', 'w') as f:
f.write(s) #fにsを書き込む
w 書き込み
r 読み込み
rb バイナリで読み込み
w+ 新しく 書き込み & 読み込みモードで開く
r+ 新しく 読み込み & 書き込みモードで開く
一行ずつ内容を読み取る
with open('test.txt', 'r') as f:
while True:
line = f.readline()
print(line, end='')
if not line:
break
チャンクごとに読み取る
with open('test.txt', 'r') as f:
while True:
chunk = 2
line = f.read(chunk)
print(line)
if not line:
break
text.txtは初期位置はどこになってるか
with open('test.txt', 'r') as f:
f.tell() いまファイル内のどこですか?ってこと
f.seek(5) 改行含めて5文字目に移動した
f.read(1) Bの一文字目が出てくる。json
import json
#jは辞書型
j = {
"employee":
[
{"id": 111, "name": "Mike"},
{"id": 222, "name": "Nancy"}
]
}
a = json.dumps(j) #辞書型をJSON型に変換
b = json.loads(a) #JSON型を辞書型に変換
print(a)
print(b)
with open('test.json', 'w') as f:
json.dump(j, f, ensure_ascii=False)
#辞書型をfに書き込み日本語文字化けを防ぐ
jsonファイルを辞書型として読み込む
with open('test.json', 'r') as f:
print(json.load(f))テンプレート
$の変数に代入できる
design/email_template.txt
"""\
Hi $name.
$contents
Have a good day
"""
import string
with open('design/email_template.txt', 'r') as f:
t = string.Template(f.read())
contents = t.substitute(name='Tom', $contents='How are you?')
print(contents)import csv
with open('test.csv', 'w') as csv_file:
fieldnames = ['Name', 'Count']
writer = csv.DictWriter(csv_file, fieldnames)
writer.writeheader()
writer.writerow({'Name': 'A'}, {'Count': '1'})
writer.writerow({'Name': 'B'}, {'Count': '2'})
with open('test.csv', 'r') as csv_file:
reader = csv.DictReader(csv_file)
for row in reader:
print(row['Name'], row['Count'])import os
os.path.exists('text.txt') ファイルが存在する?
os.path.isfile('text.txt') これはファイル?
os.path.isdir('design') これはフォルダー?
os.rename('test.txt', 'rename.txt') 名前を変更
os.remove('test.txt') ファイルを削除
os.mkdir('test_dir') フォルダを作成
os.rmdir('test_dir') フォルダを削除
os.symlink('renamed.txt', 'symlink.txt') ショートカットファイル
os.listdir('test_dir') ディレクトリの中のディレクトリのリスト
test_dir
- test_dir2
import pathlib
import glob
import shutil
pathlib.Path('test_dir/test_dir2/empty.txt').touch() 空のファイル作成
shutil.copy('test_dir/test_dir2/empty.txt', 'test_dir/test_dir2/empty2.txt')ファイルをコピー
glob.glob('test_dir/test_dir2/*') test_dir2にある全てのファイルは?オブジェクトとクラス
.capitalize()は内蔵されているclass strにあるメソッドの一つ。
s = 'fdsfsafiefa'
s.capitalize()Personクラスでオブジェクトを作成
class Person(object):
def say_something(self):
print('こんにちは')
person = Person()
person.say_something() objectはなくても可能。必ずselfを引数にとる。Personクラスから、personオブジェクトを作成。クラスの中のメソッドsay_something()を呼び出す。つまり、Pythonは、機能になるメソッドがいろいろ入ってるpersonを生成して、他に当てはめて使う。ここでいうpersonを、オブジェクトまたはインスタンスという。
__ init __ は初期化処理。コンストラクタという。__ init __ は必ず実行されるメソッド。だから、「初期化処理」とも言う。必ず最初に実行されるから。
class Person(object):
def __init__(self, name):
self.name = name
def say_something(self):
print(f'I am {self.name}.')
person = Person('Mike')
person.say_something()クラスの中のメソッドを呼び出す。2つ目にあるsay_somethingメソッドの中で、meowメソッドを呼び出している。meowメソッドは引数にnum(数字)をとる
class Person(object):
def __init__(self, name):
self.name = name
def say_something(self):
print(f'こんにちは。私の名前は{self.name}です。')
self.meow(10)
def meow(self, num):
print('meow' * num)
person = Person('Mike')
person.say_something()PythonでWEBサイトとやりとり
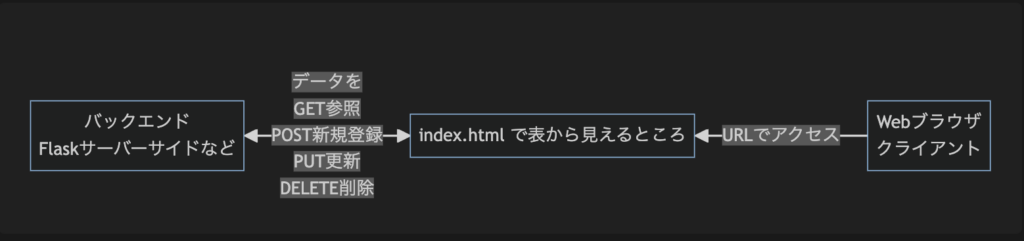
GET headerに入れて見えたまま渡すイメージ。言うなれば郵便局員には中身が見えてしまう直筆ハガキ。Webサーバーのjsonを処理してみよう。
# urllib
import urllib.request
import json
url = 'http://httpbin.org/get'
with urllib.request.urlopen(url) as f:
r = json.loads(f.read().decode('utf-8'))
print(r)
print(type(r))
f.read().decode('utf-8')の時点では中身はjson
json.loads()で辞書型に変換
# ただ、urllibはそこまで使わない。requestsの方がいい。
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=payload, timeout=5)
print(r.status_code)
print(r.text)
print(r.json())POST POSTはデータ登録で用いる。例えばWEBサイトに情報を登録するのに、丸見えになってWEBサーバーに送ったら嫌だ。だから、エンコードしたデータ(この場合はreq)に包んであげて、情報を渡す。封筒に入れて渡すイメージ。
# urllib
import urllib.request
import json
payload = {"key1": "value1", "key2": "value2"}
payload = json.dumps(payload).encode('utf-8')
req = urllib.request.Request(
'http://httpbin.org/post', data=payload, method='POST')
url,パラメーターを渡す
with urllib.request.urlopen(req) as f:
print(json.loads(f.read().decode('utf-8')))
# requests
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=payload)
引数dataに渡すだけでいい
print(r.status_code)
print(r.text)
print(r.json())PUT DELETE
r = requests.put('http://httpbin.org/put', data=payload) PUT 情報の更新
r = requests.delete('http://httpbin.org/delete', data=payload) DELETE 情報の削除並列化
処理のさせ方をこっちが指定することで、メモリを効率よく使うことができる。例えば先に処理させたい関数を先にやってと明示して、その後で次のメモリに処理させたい関数を起動する、って指定をできる。ロックという。
ロギング
- CRITICAL
- ERROR
- WARNING
- INFO
- DEBUG